
State-Driven Agent Architecture
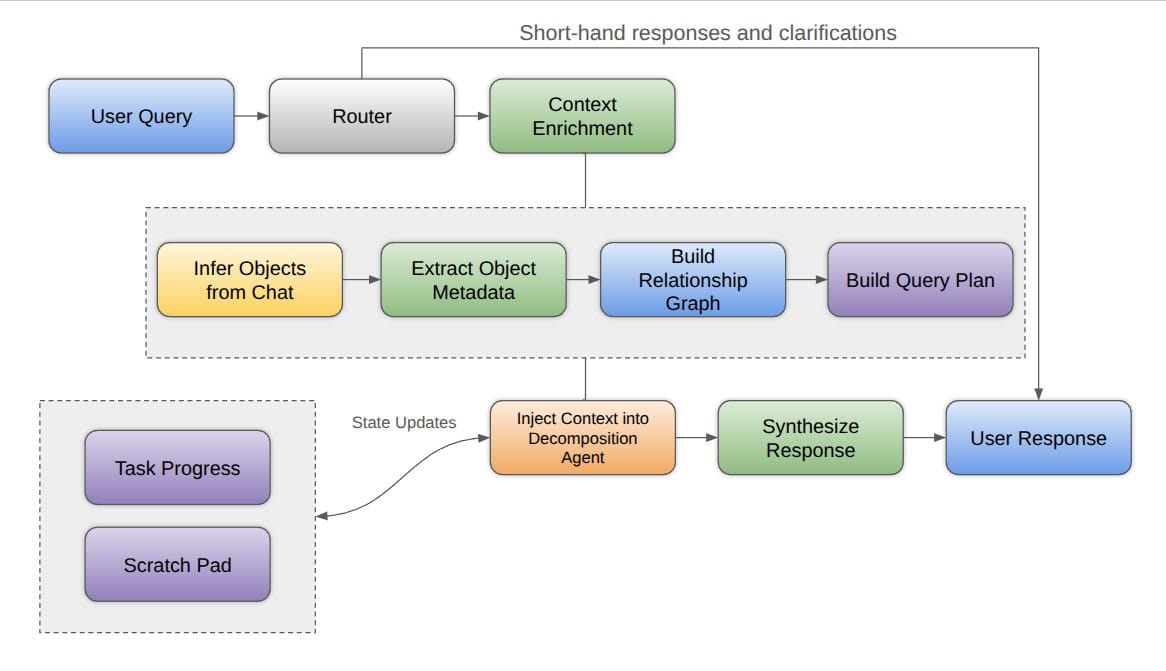
Overview
When working with a few customers, we wanted to identify simpler ways of interacting with SalesForce objects on the go for a few operational personas such as the Sales Lead, and the Operator. We designed a solution that would (hopefully) reduce the each persona's operational surface area and reduce the time to insight for these two personas to allow them to focus on the outputs, rather than the inputs.
The goals we defined were simple:
- A traditional ReAct agent would not understand contextually, what exists in a SalesForce organization, and also how to query it. An optimized agent must be able to understand objects and understand how to query across objects to provide concise cross-object answers to the User.
- Leveraging tools like LangGraph and LangChain, we see limitations in token context length over long reasoning sequences for standard ReAct agents, so our agent must maintain a clean and concise state to maximize the utility of the context (scratch pads and custom context management), while completing a sequence of steps successfully.
High-Level Architecture
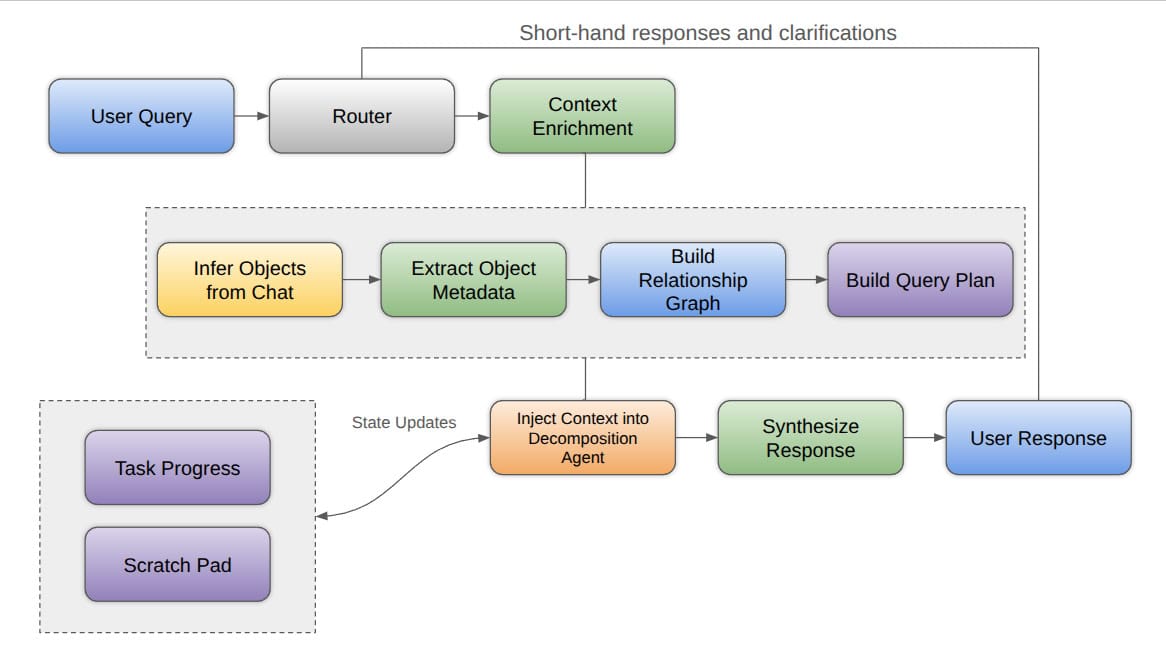
Query Router
The goal of the query router is to reduce complexity of the agent response on a per request basis. The Query Router injects a decision-making step before any heavy compute is applied a task, to respond quicker to the user, ask for clarifications, and reduce overall unnecessary calls to an LLM is made. The router can decide to either go immediately back to a User Response, or pass the request onto the DecompositionAgent which unpacks the request into sub-tasks. There are various router architectures – in our case we use a lower cost LLM to interpret the requests.
Context Enrichment
Overview
The most critical aspect of this agent is its context enrichment. When working with an agent's context in general, it is imperative to manage this as a state, and less of a growing body of text. As we know and have seen, context growth can lead to a reduction in overall response accuracy, and affect the agent's ability to reason over more complex multi-step problems. This is generally defined as context rot, and can be assessed with "needle in a haystack" assessments and other various techniques. Therefore, by focusing on state management and memories, we can prioritize higher-value data for LLM to reflect on. At the end of the day, conceptually, shorter contexts yield better performance.
General Context Example

For simpler implementations, you can achieve a level of "Good" context management by essentially passing conversation history, however there are context limits with almost all production LLM implementations (size and cost) and may generally fail for required custom agent solutions.
SalesForce Context Example
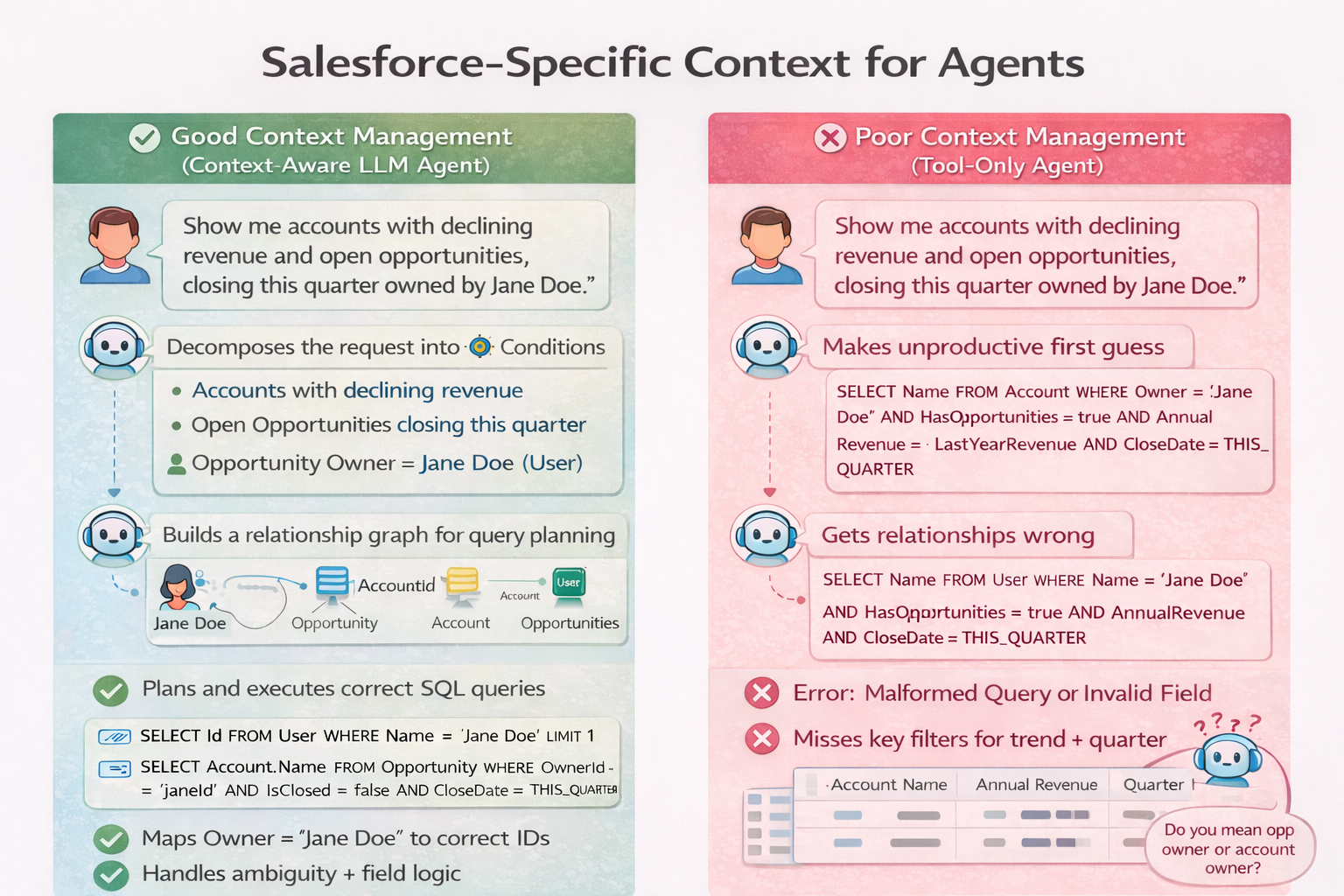
In terms of SalesForce, and our goals, the agent must first understand a few things:
- How to use and write SOQL (Internal LLM knowledge with some guidance)
- What are the existing SalesForce objects (SalesForce dataset)
- What are the objects we are talking about (Understanding of question)
- How are those objects related (Natively, or for the specific query)
This implies that by default, the agent would be naive about various questions that pertain to the business's specific SalesForce objects and relationships. To solve this, we implemented four steps that turned a naive agent into a very strong SalesForce Analyst for an organization.
Step 1: Object Cache
The goal of the object cache is to have a local reflection of objects for quick access to eliminate any direct SalesForce calls for the agent. We only store metadata, and directly query SalesForce during the query executions only, and on an interval to synchronize the object cache.
Step 2: Query Interpretation
User
Show me accounts with declining revenue and open opportunities, closing this quarter, owned by John Doe.
We first work on object extraction to identify the potential objects in question. In the example above, we identify a few objects, Accounts and Opportunities. We assume that the person named is either a PersonAccount or a User. Because "owned" is mentioned, the Agent can infer that this is a relation inside the Opportunity. Therefore, to start, we assume Opportunities, Accounts, and Users are the objects we may need to interact with. In our case, we injected a few default objects that we would essentially allow the agent to reason over whether or not needed.
Included objects: ['Account', 'Opportunity', 'RecordType', 'User']Step 3: Relationship Graph
From the query interpretation, we can build out the list of relationships from Opportunity to Account via Account (Lookup), and Opportunity to Owner via Owner (Lookup). Whether it's one, two, or three hops, we generally have enough information to traverse and generate the plan end to end.
Opportunity:
→ Account via AccountId (relationship: Account)
→ User via OwnerId (relationship: Owner)Step 4: Query Plan
Once we have the relationships defined, we step through the logical sequence nodes in the graph to deterministically plan the query (not via an LLM). This directs the agent to use this plan to do the tasks in this order. The outcome is the expected order of operations to answer the query end to end. For additional clarity, we provide specific patterns to use for certain types of operations and relationships that we identify.
CROSS-OBJECT QUERY PLAN:
Objects: Opportunity → Account
Relationship: Account.Id links to Opportunity.Account
Step 1: Get User record named 'Foo Baz'
Step 2: Get Opportunity.owner via User.Id
...In summary, if you can plan your execution before passing them to the LLM, then the LLM is more likely to complete the steps required in the correct order.
Caveat
Further work may yield that we can avoid any additional LLM-based decomposition by generating SOQL directly via the query plan (i.e. delegate to a "worker" that can do the job versus an LLM that needs to reason before executing) with some additional inference-based labeling and keyword extraction. The current benefit of LLM-based reasoning for each query step is that based on the original prompt and the current object and query, the LLM can reasonably decide what fields are relevant to the question and return those at will versus pre-determined assumptions that would be made when skipping the LLM reasoner. Architect this component as you see fit.
Decomposition Agent
Onto the decomposition agent, we now have enough information to answer the user's query. The first step the DecompositionAgent executes is a generating a set of tasks.
Added subtask root_1: Confirm schema and fields to use. Primary objects: Opportunity (child) and Accounts
Added subtask root_2: Find Jane Doe's User Id so we can filter opportunities by owner. Run query_salesforce tool.
Added subtask root_3: Query Accounts with their open Opportunities (child subquery) that are closing THIS_QUARTER.
Added subtask root_4: Format and present results grouped by Account. For each Account show: Account Name, Opportunity Name, Close Date, Amount, Stage, and Owner.Once the tasks have been unpacked, the Decomposition Agent can decide (in our architecture) whether to execute the task itself or pass it onto a simple LLM or a more advanced ReAct agent. Each step is passed along as state, not part of the LLM context itself, so that each subsequent step can leverage the previous step's information. This architecture can and may vary depending on your specific needs, however in our case, we were consistently able to ask our agent for BI-style requests and get successful answers across multiple objects using the above approach. The data states are updated till all tasks are completed.
Synthesis and Response
Our synthesis step is to simply return a natural language response (via simple LLM inference), based on the available data. We do this by sending data summary snippets to the agent, and formatting the finalized state-based payloads in either chart or table form along with a summarized LLM response.
Key Takeaways
The Salesforce example illustrates the broader point behind these takeaways. A naive LLM, even with tool access, cannot reliably answer cross-object business questions without context. By externalizing schema awareness, relationship traversal, and query planning into explicit system components, we can transform a generic LLM into a reliable Salesforce analyst, without increasing model complexity. This pattern generalizes to any system built on relational data and defined schemas.
- LLMs are not domain-aware by default
Even strong ReAct-style agents lack understanding of your in-depth domain-specific context. Domain intelligence must be injected through metadata, structure, and planning, not prompt engineering alone. - Context should be treated as state, not conversation history
Unbounded context growth leads to degraded reasoning and higher cost. Managing agent memory as a structured state produces more reliable multi-step reasoning and avoids context rot. - Deterministic planning can improve emergent agent reasoning
In our case, and in general for relational systems, pre-computing object relationships and deterministically generating query plans. - Production agents are systems, not prompts
Reliability, scalability, and improved correctness emerges from architecture – routing, state management, and memory – not from increasingly complex prompts.
References
